
Atenção pode ser tudo que você precisa, mas será que você precisa de tudo?

(Imagem gerada por DALL·E)
Na era da engenharia de prompts, ainda há espaço para treinamento e desenvolvimento de modelos ou devemos apenas nos ajoelhar diante do GPT e seus sósias?
Os grandes modelos de linguagem (LLMs) tornaram-se incrivelmente populares nos últimos anos, com modelos como o GPT gerando texto semelhante ao humano. Nos bastidores, esses modelos usam arquiteturas diferentes otimizadas para finalidades diferentes.
Embora o modelo tradicional Codificador-Decodificador (exemplificado pelo BERT da Google) seja mais complexo do que seus equivalentes apenas Decodificadores, o GPT da OpenAI atinge um desempenho excepcional seguindo a última configuração. Como é que um modelo menos complexo é melhor que um mais complexo? Além disso, dadas as incríveis capacidades da GPT, podemos nos sentir tentados a usá-lo até mesmo para as tarefas mais básicas de PNL, como classificação de texto e análise de sentimentos. Mas você deveria fazer isso?
Neste artigo, veremos como é usada a arquitetura do modelo que introduziu os fundamentos da atenção e dos transformadores e como podemos separá-la para obter resultados melhores e mais viáveis para cada caso de uso específico.
Modelos Transformador e Codificador-Decodificador
A arquitetura do Codificador-Decodificador contém dois componentes principais – um codificador e um decodificador (duh). Os modelos Codificadores-Decodificadores são normalmente usados em tarefas sequência a sequência, como tradução e resumo. O modelo Transformer (Transformador), proposto no famoso artigo “Attention Is All You Need” [1], é uma instância específica da arquitetura Codificador-Decodificador que usa mecanismos de autoatenção para melhorar as deficiências de modelos anteriores, como LSTMs e GRUs.
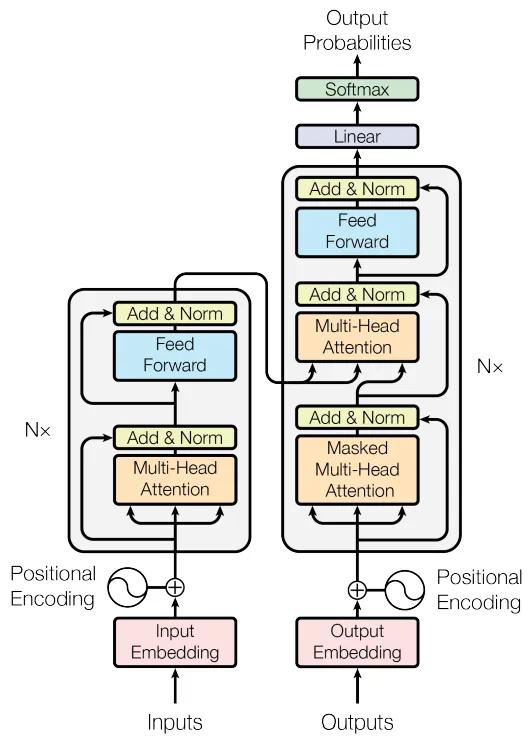
A arquitetura do Codificador-Decodificador Transformador (fonte: [1])
Na figura acima, o Encoder (codificador) é o bloco do lado esquerdo e o Decoder (decodificador) é o bloco da direita. O codificador recebe o texto de entrada e o codifica em uma representação vetorial densa. Podemos pensar nessa representação codificada como o significado semântico e o contexto da entrada. O decodificador então pega essa representação e gera o texto de saída token por token. É por isso que, na figura, você pode ver as Outputs (Saídas) sendo inseridas no Decoder: isso representa os tokens de saída sendo inseridos de volta, um por um. Naturalmente, o Decoder precisa saber quando começar e quando parar: estes são representados por tokens especiais que definem o início e o fim de um texto.
Modelos Somente Codificadores
Os modelos somente Codificadores contêm apenas o componente codificador. Esses modelos codificam o texto de entrada em uma representação vetorial semântica, mas não geram nenhum texto de saída. Em vez de conectar a saída do codificador a um decodificador, sua saída é então conectada a um cabeçote treinado para um caso de uso específico (normalmente não a geração de texto).
Esses modelos são úteis para extração de recursos de texto. Eles são treinados em tarefas que não requerem mapeamento sequência a sequência. A saída final do codificador pode ser usada de várias maneiras, dependendo da tarefa – como classificação de tokens, classificação de sequências ou até mesmo como recursos para outros modelos de aprendizado de máquina.
Um exemplo de modelo somente Codificador é o BERT [2]. Ele usa a parte do codificador do modelo original Transformador para gerar uma representação de tamanho fixo de uma sequência de texto de entrada, que pode então ser ajustada para várias tarefas, como classificação de texto e reconhecimento de entidade nomeada. Como o BERT utiliza apenas o componente codificador, ele não é inerentemente adequado para tarefas de sequência a sequência fora do comum, ao contrário da arquitetura completa do Transformador Codificador-Decodificador. Em vez disso, o BERT é geralmente usado para tarefas que exigem a compreensão do contexto de tokens individuais em uma sequência de texto.
Modelos Somente Decodificadores
Modelos somente Decodificadores, como GPT [3, 4], contém apenas a parte do decodificador. A entrada para modelos somente Decodificadores é uma sequência de tokens que serve como contexto para a geração de tokens subsequentes.
Enquanto os Transformadores tradicionais (Codificador-Decodificador) são treinados para tarefas sequência a sequência, os modelos somente Decodificadores são treinados para prever o próximo token em uma sequência, dados os tokens anteriores. Esses modelos são normalmente auto-regressivos, o que significa que eles geram texto de saída token por token, condicionando o próximo token aos tokens gerados anteriormente. Isso difere do Codificador-Decodificador tradicional, onde o codificador processa toda a sequência de entrada de uma só vez e o decodificador gera a sequência de saída token por token.
Os modelos somente Decodificadores são geralmente usados para tarefas que requerem a geração de texto ou outros tipos de dados a partir de algum contexto inicial. Isso inclui preenchimento de texto, geração de texto e até tarefas como geração de imagens no caso de modelos como DALL-E [5].
Como incluem apenas o decodificador, esses modelos podem ter menos parâmetros do que um Transformador completo que inclui um codificador e um decodificador. No entanto, modelos como GPT-3 e GPT-4 mostraram que arquiteturas somente decodificadoras podem ser dimensionadas para um grande número de parâmetros.
Por que não usar GPT para tudo?
Bem, você poderia. Na maioria dos casos, os modelos do tipo GPT podem gerar texto com sucesso e compreender o contexto sem um codificador ao seu lado. Além disso, estamos empiricamente convencidos de que esses modelos também podem realizar tarefas como classificação de texto e análise de sentimentos com alta precisão: ao fornecer ao GPT um prompt adequado, suas capacidades são quase infinitas. Mas, como acontece com todas as coisas maravilhosas, não é de graça. Longe disso, na verdade.
A tabela abaixo mostra como o BERT pode obter melhores resultados do que o GPT, especialmente para tarefas semânticas e de classificação (para obter mais informações sobre o conjunto de dados e benchmark utilizado, consulte [6]). Lembre-se de que esta é uma referência à primeira versão do GPT, não à mais recente.
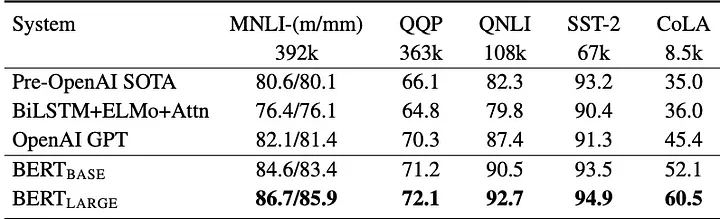
Comparando BERT com GPT (Fonte: [2])
Como Cientistas de Dados, temos que fazer uma escolha. E a escolha depende da aplicação final. Escolher uma solução Codificador-Decodificador apenas porque ela fornece boa precisão pode aumentar desnecessariamente o tempo e o custo de desenvolvimento de um projeto. O mesmo se aplica à seleção de um modelo somente Decodificadores como o GPT: embora possa classificar textos ou detectar sentimentos em frases, ele tem o preço de um modelo gigantesco. Para soluções básicas, como classificação de texto e análise de sentimentos, os modelos somente de Codificadores podem ser uma solução interna adequada e de baixo custo.
Resumo
Em relação ao seu funcionamento interno:
- Os codificadores extraem o significado semântico e o contexto do texto, gerando uma representação dos mesmos.
- Os decodificadores geram texto a partir de texto, prevendo qual é a próxima palavra mais provável, dada a anterior.
Ao unir forças, um modelo Codificador-Decodificador gera texto extraindo primeiro um significado semântico e um contexto de uma entrada (usando o Encoder) e depois prevendo palavras uma por uma usando uma combinação desses significados e da palavra anterior que acabou de ser prevista (usando o Decoder).
- Os modelos Codificadores-Decodificadores oferecem maior flexibilidade, mas são mais lentos para treinar. Eles são usados para tradução e resumo.
- Os modelos somente Codificadores são eficientes para classificação e extração de recursos, mas não podem gerar texto.
- Os modelos somente Decodificadores são fluentes na geração de texto, como conversas.
Referências
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems. arXiv:1706.03762
[2] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805
[3] Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. OpenAI Technical Report
[4] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Technical Report
[5] Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., & Sutskever, I. (2021). DALL·E: Creating images from text. OpenAI Blog
[6] Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2018). GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. arXiv:1804.07461
Em Português Simples
Obrigado por fazer parte da nossa comunidade! Antes de você ir:
- Não deixe de bater palmas e seguir o escritor! 👏
- Você pode encontrar ainda mais conteúdo em PlainEnglish.io 🚀
- Inscreva-se em nossa newsletter semanal gratuita. 🗞️
- Siga-nos no Twitter(X), LinkedIn, YouTube e Discord.
Este artigo foi escrito por Gennaro S. Rodrigues e traduzido por Isabela Curado Nehme. Seu original pode ser lido aqui.







Top comments (0)