
29 de junho de 2023
Todos nós já ouvimos falar do Stable Diffusion (Difusão Estável), uma ferramenta de IA generativa que cria imagens a partir de texto (e pode fazer muito mais também), mas como isso realmente funciona?
Compreendendo os modelos de difusão:
Um modelo de difusão é treinado através da adição de ruído gerado por um programador de ruído a uma imagem (ou uma representação “comprimida” de uma imagem, como veremos mais adiante) e fazendo o modelo reverter esse processo pouco a pouco, em várias etapas. Vamos dar uma olhada no processo:
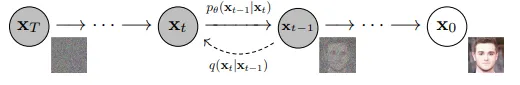
x0 é a imagem inicial e xT é a imagem com ruído final, enquanto xt e xt-1 são etapas intermediárias.
Primeiro, o ruído Gaussiano é adicionado à imagem inicial ao longo de muitas etapas (1000 etapas de acordo com o artigo formativo Denoising Diffusion Probabilistic Models (DDPM)), para alcançar o que é ruído essencialmente puro (um ponto amostrado aleatoriamente de uma distribuição Gaussiana/Normal). A programação da variância β1, . . . , βT determina a quantidade de ruído adicionada em cada etapa de acordo com as equações abaixo.
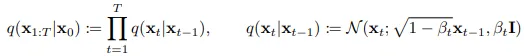
q(x) é a distribuição dos dados, xi representa a imagem em cada etapa do processo de ruído, N *é a distribuição Normal, **I *é uma matriz identidade. **- Eq(1)
Isso é chamado de processo para a frente (forward process). Em seguida, essa equação foi um pouco reescrita, definindo α t=1- β t e α¯ t como o produto de todos os αts do intervalo de tempo t=1 ao intervalo de tempo t= t. Agora, a Eq(1) é reescrita como:
![]()
Eq(2)
Esse foi o processo de difusão para a frente, criando ruído Gaussiano a partir de imagens. Agora começa o processo de difusão reversa para recuperar a imagem x0 do ruído xT, etapa por etapa. Infelizmente, isso exige que tenhamos conhecimento de toda a distribuição de dados, o que não é fácil e, por isso, modelamos essa distribuição de dados da seguinte maneira:
![]()
-Eq(3)
Isto significa essencialmente: a distribuição de dados prevista pelo modelo xt-1 no intervalo de tempo t-1, dada a distribuição de dados xt no intervalo de tempo t, é uma distribuição normal com média µθ(xt,t) e matriz de covariância Σθ(xt,t).
Na prática, os autores do DDPM definiram Σθ(xt,t) como a matriz diagonal (σt)²I, onde σt foi um hiperparâmetro definido para cada intervalo de tempo t. Eles também decidiram modelar µθ(xt,t) da seguinte forma:
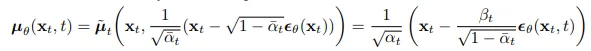
εθ é um aproximador de funções destinado a prever ε a partir de xt, em que ε é aproximadamente o ruído que foi adicionado na etapa t-1 do processo para frente. Na prática, εθ é uma U-net.
Para treinar a U-net, minimiza-se o limite variacional da log-verossimilhança (log-likelihood) negativa (NLL) (basicamente, uma representação de quão próximo uma distribuição de probabilidade reflete a distribuição do conjunto de dados; quanto mais baixa for a NLL, mais próxima ela reflete o conjunto de dados) da distribuição de dados prevista.
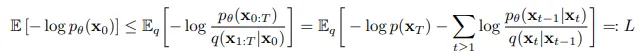
-Eq(3)
Usando a definição de Divergência KL (Divergência de Kullback-Liebler, uma medida estatística da diferença entre duas distribuições de probabilidade) abaixo:
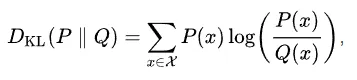
Definição da divergência KL da distribuição P em relação à distribuição Q. Observe que esta é assimétrica entre P e Q.
O termo de perda simplifica-se a:
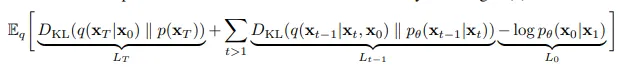
Em suma, os autores usam os seguintes algoritmos para o treinamento e a amostragem:

~ significa amostragem a partir de uma distribuição de probabilidades.
Observe que, durante o treinamento, um intervalo de tempo aleatório é escolhido e a norma L2 (também conhecida como distância euclidiana) entre o ruído previsto multiplicado por fatores de escala e o ruído real adicionado é calculada, em vez de fazer a amostragem de todas as etapas em cada imagem.
Outras melhorias foram feitas para essa classe de modelos após o artigo do DDPM, incluindo uma amostragem mais rápida por meio de “saltos” de intervalos de tempo durante a inferência e orientação do classificador, que usa um classificador de imagem treinado em um grande conjunto de dados (como ImageNet) para orientar a previsão de ruído de modo que o resultado final seja da classe desejada. Isso permitiu que os modelos de difusão superassem os modelos baseados em GAN (Redes Adversárias Generativas) na geração de imagens. A orientação sem classificador, como o nome sugere, ajuda a guiar a imagem final em direção à classe necessária, sem usar os gradientes de um modelo classificador.
Vejamos agora todos os componentes da difusão estável:
VAE:
Lembra de quando eu disse que os modelos de difusão também podem funcionar em representações comprimidas de uma imagem? O Stable Diffusion é, na verdade, um desses modelos de difusão, conhecidos como modelos de difusão latente (LDMs). Esses modelos utilizam um codificador automático variacional (Variational Autoencoder), ou VAE, para comprimir uma imagem em um espaço latente menor, adicionar ruído a esses latentes durante o treinamento e expandir os latentes gerados para as dimensões da imagem durante a inferência (ou seja, a U-net funciona inteiramente no espaço latente e não no espaço da imagem). A difusão estável usa um VAE que converte cada bloco de dimensões [1x3x8x8] em um bloco de [1x4x1x1]. Assim, uma imagem RGB de resolução 512x512 é convertida em latentes de dimensões [1x4x64x64]. O modelo de U-net, explicado abaixo, trabalha efetivamente com esses latentes, não com imagens.
O principal benefício de usar um VAE é que o modelo tem que trabalhar em um espaço menor ((1x3x512x512)/(1x4x64x64)=48, então o espaço latente é 48 vezes menor para imagens de 512x512), portanto, o treinamento e a inferência são mais rápidos.
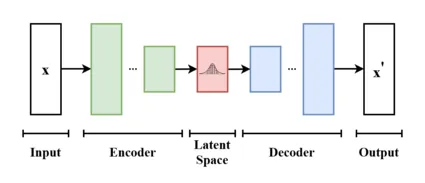
Um diagrama simples e de alto nível de um VAE. Imagem deste link.
Programador de ruído:
O programador dimensiona o ruído previsto pelo modelo de forma adequada antes de removê-lo da imagem com ruído. As U-nets para modelos de difusão são geralmente treinadas usando um programador DDPM (cujas equações foram descritas acima), mas, normalmente, são usados outros programadores para amostragem, que ajudam a acelerar significativamente a geração da imagem. Existem vários programadores: DDIM, PNDM e Euler são alguns deles. Eu recomendo dar uma olhada neste link para ver alguns dos programadores mais usados.
U-Net:
Originalmente desenvolvidos para a segmentação rápida de imagens médicas, as U-nets tornaram-se muito populares para tarefas em que a entrada/saída tem as mesmas dimensões.
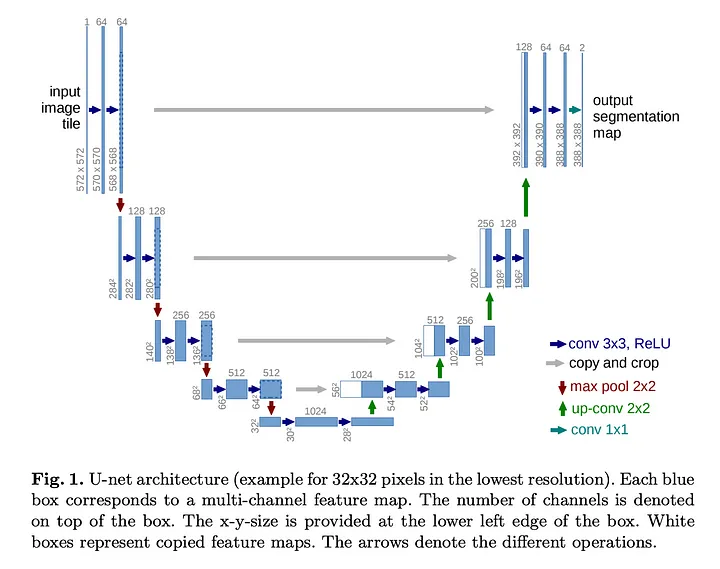
Diagrama da U-net do artigo U-net original de 2015. A U-net de SD é significativamente mais complexa.
Uma U-net começa por comprimir as informações para um espaço menor na parte descendente do “U”, depois as processa na parte inferior do “U” e, por fim, expande-as para o tamanho de entrada original na parte ascendente do “U”.
O Stable Diffusion usa um modelo de U-net bem grande, com cerca de 859 milhões de parâmetros, com muitas camadas de auto-atenção ou self-attention (sobre o vetor que está sendo processado) e atenção cruzada ou cross-attention (entre o vetor sendo processado e a saída do codificador de texto, explicada abaixo) construídas nele. Isso ajuda a orientar a previsão de ruído da U-net em cada etapa.
Codificador de texto:
O Stable Diffusion usa um codificador de texto CLIP (Contrastive-Language-Image-Pretraining ou pré-treinamento com contraste entre linguagem e imagem) para transformar os prompts em vetores de incorporação de texto de dimensões [1,77,768], se não estiver usando CFG, para orientar as previsões de ruído da U-net acima mencionadas. A metodologia CLIP treina conjuntamente um codificador de texto (BERT, neste caso) e um codificador de imagem (um Vision Transformer, ou ViT aqui).
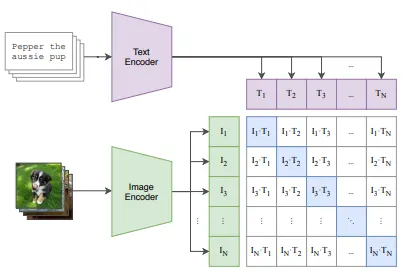
Uma pequena imagem do documento CLIP, que demonstra o treinamento. Normalmente, um tamanho de lote muito grande de pares imagem-texto é usado para proporcionar contraste entre diferentes textos e imagens.
O treinamento CLIP basicamente maximiza a semelhança do cosseno (produto escalar) das incorporações de imagem produzidas pelo ViT com as incorporações de legenda de imagem correspondentes geradas pelo modelo BERT. Isso resulta em um espaço de incorporação em que os vetores de incorporação de texto e imagem estão próximos e, assim, o codificador de texto tem uma “ideia” do aspecto de uma imagem, dado um pedaço de texto. Assim, os prompts são convertidos em vetores de incorporação que alimentam a U-net. Em seguida, um mecanismo de atenção cruzada, com o vetor de consulta definido para os latentes de entrada e os vetores de chave e valor definidos para os vetores de incorporação, orienta o processo de geração de ruído da U-net.
Como tudo se encaixa:
Aqui está um diagrama de como tudo está organizado. O E e o D representam o codificador/decodificador VAE, respectivamente, enquanto o τθ aqui é o codificador de texto CLIP.
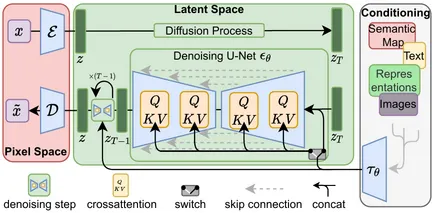
Fonte da imagem: Compvis
Aqui estão as etapas que ocorrem durante a inferência:
- Primeiro, o prompt de entrada é convertido em incorporações de texto pelo codificador de texto CLIP.
- Em seguida, latentes completamente aleatórios são amostrados a partir do espaço latente e, em seguida, inseridos na U-net para terem os ruídos eliminados. As incorporações de texto também são alimentadas na U-net para orientar o processo de redução de ruído por meio da atenção cruzada, de modo que a imagem se pareça com o que queremos.
- A U-net então prevê o ruído, dado o ruído aleatório no espaço latente e as incorporações de texto.
- O ruído previsto pela U-net é então dimensionado de forma apropriada, de acordo com os parâmetros do programador, e removido dos latentes.
- As etapas 3 e 4 são repetidas por algumas etapas (dependendo do hiperparâmetro de etapas definidas, 50 é típico para DDIM, 1000 para DDPM etc.), exceto aquelas em que os latentes para cada etapa são as saídas latentes sem ruído da etapa anterior.
- Depois que o número definido de etapas for concluído, o VAE converte os latentes na imagem de saída final.
Alternativas:
Além do Stable Diffusion, existem outros modelos de difusão abertos ao público para serem utilizados. O Midjourney é bastante conhecido, mas modelos como o Deepfloyd-IF ou o Kandinsky ainda não são tão famosos.
Pesquisa:
Os modelos de difusão estão sendo fortemente pesquisados e todos os dias se descobrem coisas novas e excitantes. Aqui estão algumas coisas que eu acho interessantes:
- Cones (ajuda os modelos de difusão a memorizar assuntos, com parâmetros mínimos);
- DragDiffusion (permite a edição de imagens ao arrastar partes da imagem);
- Usando LLMs como GPT-3.5 para orientar modelos de difusão.
Bem, era isso! Espero que tenha sido pelo menos um pouco útil. Sinta-se à vontade para comentar sobre possíveis melhorias. Agradeço à StabilityAI e ao LAION por ajudar a tornar gratuitas (ou de código aberto) essas excelentes ferramentas/conjuntos de dados de ML para que todos possam usar. Eu não poderia ter escrito este artigo sem as fontes citadas abaixo, portanto, dê uma olhada, são ótimas leituras.
Fontes:
- Weng, Lilian. (julho de 2021). What are diffusion models (o que são modelos de difusão)? Lil'Log. https://lilianweng.github.io/posts/2021-07-11-diffusion-models/.
- https://arxiv.org/abs/2006.11239v2
- https://arxiv.org/abs/1505.04597
- https://arxiv.org/abs/2103.00020
- https://arxiv.org/abs/1810.04805
- https://arxiv.org/abs/2010.11929
- https://arxiv.org/abs/1312.6114
- https://arxiv.org/abs/2112.10752
Esse artigo foi escrito por J. e traduzido por Isabela Curado Nehme. Seu original pode ser lido aqui.




{kind=link}
{kind=link}
Top comments (0)